고정 헤더 영역
상세 컨텐츠
본문
건설공사 입찰은 15개의 예가 중에서 4개를 선택하여 그 평균을 사용한다.
따라서 예가의 확률은 정규분포를 따른다.
예가의 확률 정규분포를 그려보는 연습을 한다.
import itertools
import pandas as pd
import matplotlib.pyplot as plt라이브러리를 가져온다.
itertools는 반복 가능한 데이터 스트림을 처리하는 데 유용한 많은 함수와 제네레이터가 포함되어 있다고 한다.
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
판다스는 데이터 처리를 위해서, matplotlib는 시각화를 위해서 가져온다.
event=list(itertools.combinations(range(1,15),4))| 조건 | 명령어 |
| 순서는 중요하고, 중복은 허용 안될때 | itertools.permutations |
| 순서는 중요하고, 중복은 허용될때 | itertools.product |
| 순서는 중요하지 않고, 중복은 허용안될때 | itertools.combinations |
| 순서는 중요하지않고, 중복은 허용될때 | itertools.combinations_with_replacement |
itertools는 순서의 중요성과 중복의 허용에 따라 4가지 명령어를 사용할 수 있다.
예가 선정의 경우, 순서는 중요하지 않지만, 같은 숫자가 2번 뽑힐수 없으므로 itertools.combinations를 사용하였다.
조건으로는 1에서 15까지의 숫자 중 4개를 뽑는 것으로 했다. (range(1,15),4)
결과값은 전체 경우의 수를 리스트로 돌려주며,
각각의 리스트 값은 뽑힌 4개의 숫자가 담긴 튜플로 준다.
df=pd.DataFrame(event,columns=['first','second','third','fourth'])이 리스트를 데이터프레임에 담는다.
이때 칼럼명을 first, second, third, fourth로 임의로 설정하였다.
df['sum']=df['first']+df['second']+df['third']+df['fourth']sum이라는 칼럼에 각각의 칼럼의 합을 담았다.
최종예가는 4개 예가의 평균이기 때문이다.
(원래는 합이 아니라 평균 - 즉 4로 나눈 값 - 이어야 하지만, 귀차니즘으로 일단 합으로만 만들었다.)
yega = df['sum'].value_counts().rename_axis('unique_values').reset_index(name='counts')yega라는 데이터프레임에 sum의 value_counts 값을 담았다.
unique_values 칼럼에는 고유값 (합)을 counts에는 빈도수를 담았다.
plt.bar(yega['unique_values'], yega['counts'])
plt.show()bar 그래프로 빈도수를 예가별로 그렸다.
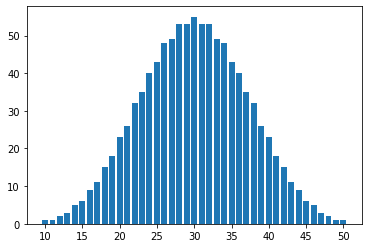
정규분포 하는 것을 알수 있다.
최저값은 10, 최고값은 50, 중간값은 30이었다.
중간값에서의 빈도수는 55이고, 최고(최저)값에서의 빈도수는 1이었다.
전체 빈도수의 합은 1001였다.
전체 빈도중 25이상 35이하가 543개로 54.3%에 해당한다.
즉, 40개의 가능한 예가중 10개가 54.3%에 해당한다는 뜻이다.
예가범위를 -3%에서 +3%로 산정하였을때, -0.5%에서 +0.5%사이에 54.3%가 떨어진다는 뜻이다.
전체 빈도중 23이상 37이하가 697개로 69.7%에 해당한다.
즉, 40개의 가능한 예가중 16개가 69.7%에 해당한다는 뜻이다.
예가범위를 -3%에서 +3%로 산정하였을때, -0.7%에서 +0.7%사이에 69.7%가 떨어진다는 뜻이다.
결론은 입찰시 아무리 숫자를 날리는 경우라도 +/- 0.7%를 넘지 않아야 한다는 뜻이다.
'4차' 카테고리의 다른 글
| 판다스 데이터프레임으로 json파일 불러오기 (0) | 2020.03.08 |
|---|---|
| 광역단체별 공시지가 파일을 자치구 별로 구분하여 파일 만들기 (1) | 2020.03.06 |
| 공공데이터포털 출력결과 국문 영문 필드명 교체하기 (0) | 2020.02.29 |
| 역대 로또 데이터 크롤링 feat. 따라하기 (1) | 2020.02.28 |




